I think we are in agreement on the general idea for the FEP. It is also great that you have made a list of some of the properties that are up for FEP consideration.
Also agree with these examples, but other than examplary we need not further focus on the particulars, and just focus on the process itself. There are likely a whole bunch of cases to be considered afterwards once the process is in place.
You mean by means of the @vocab keyword? And the mention of Default Vocabularies?
I think “Vocabulary” is appropriate. For instance the JSON-LD spec also mentions:
For example, the prefix
foafmay be used as a shorthand for the Friend-of-a-Friend vocabulary.
We also have vocabularies in the same way. The Security Context vocabulary, the Mastodon Toot vocabulary, the ActivityStreams Vocabulary.
A question remains: When is something a vocabulary?
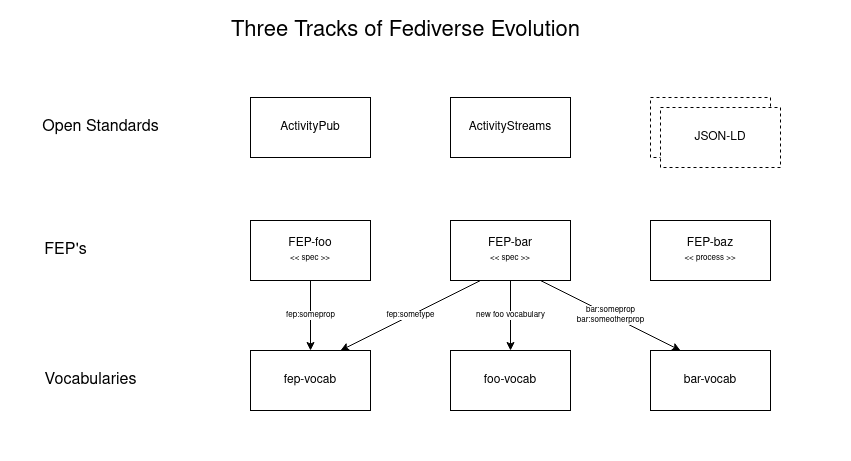
Above I mentioned in par. Human Readable that "Also note that in terms of how FEP’s relate to [vocabularies] there is no 1-to-1 mapping at the moment. And maybe there shouldn’t be one either, so that FEP’s and [vocabularies] (which define AP vocab extensions) are entirely separate.
A FEP might define one or more properties to be added to an existing vocabulary, or multiple vocabs, or introduce a new vocab, etc. Individual FEP specifications in that regard aren’t vocabularies, where each document gets their own namespace. But there still can be one universal FEP vocabulary where particular properties are added that are generic additions to the AP protocol stack.
It gets a bit confusing, but once again I see the aforemention division…
So 2) are docs, mostly related to core protocol extensions that are universal and relevant to any fedi project. And which also define the processes we use, i.e. the FEP process itself, and the Vocabulary process.
And in 3) we may have a FEP vocabulary collecting core extensions in its own @context and I like the ideas of @trwnh in the comment above, but we also get a growing set of other vocabs that are often used and their use increases general interopability, albeit sometimes in very particular domains. In this list of vocabs Mastodon might also submit their @context doc pointing to their own domain and docs location (example of a post-facto interop adoption).
It is the Process that we are defining now. How many vocabs there are and how they are named and defined is something that is a second step, imho.
But I think there’s more than just a FEP vocab (though this one is our starter for what we have already been specifying in prior FEP docs). Like e.g. I could well foresee a need to have some vocab around video platforms soon as more video-related apps are making their entrance to the fedi. Another example is the Podcasting scene that is working on their own vocabulary. See: activitypub-spec-work.