Yesterday i recognized, that i have trouble with bnodes. I’m not sure, if I understood the spec correct.
3.1 Object Identifiers
All Objects in [ActivityStreams] should have unique global identifiers. ActivityPub extends this requirement; all objects distributed by the ActivityPub protocol MUST have unique global identifiers, unless they are intentionally transient (short lived activities that are not intended to be able to be looked up, such as some kinds of chat messages or game notifications).
how is “3.1 Object Identifiers” to be understood in connection with source from “3.3 The source property” ? source does not seem to be a transient property. Is “Example 8” wrong then?
{
"@context": ["https://www.w3.org/ns/activitystreams",
{"@language": "en"}],
"type": "Note",
"id": "http://postparty.example/p/2415",
"content": "<p>I <em>really</em> like strawberries!</p>",
"source": {
"content": "I *really* like strawberries!",
"mediaType": "text/markdown"}
}
I could be wrong, but I believe "source" is not an ActivityPub/ActivityStreams object, just a JSON(-LD) object. It has no use or relevance outside of the Note it’s a part of. I suppose, though, its ID might implicitly be http://postparty.example/p/2415#source if it did need one.
“not intended to be able to be looked up” is the key part.
That makes sense, taken out of context. If one doesn’t already exist, maybe we should create an AP issue for the possible new WG to consider clarifying that part of the documentation:
What does “transient” really mean
Guidance for objects that can’t be dereferenced (but aren’t transient) be handled
There’s also the inverse case (implemented by Mastodon) where some objects with an id can’t be dereferenced. IIRC, the Follow activity is in this category.
In the specific case of the source attribute, it’s reasonable to send an anonymous object because the blank node is only associated with the referring object. However, it’s also reasonable to assign a URI and send that instead of the source object. If most servers ignore the source property, it would be more network-efficient to send the URI. However, I suspect that few or no receiving servers would use a URI for source.
I have a problem with blank nodes in principle. This is something I don’t want to support. I would also have to see how my triple store (along with my architecture) handles it.
I would then rather assign an id internally and store source as a separate object. Right now my server throws an illegalStateException in the case of blank nodes.
That’s interesting. I’m curious what is causing the exception. All triplestores I’ve used support blank nodes (a well-specified concept in RDF). The implementations I’ve used automatically assign an internal graph-private identifier to blank nodes.
Although the “you can treat AP/AS2 as plain JSON” perspective tries to hide it, every received (and published) message is a graph (in JSON-LD/RDF terms). As an example, Vocata (python rdflib) converts incoming JSON-LD activities into an RDF message graph. After validating the message graph, it merges that graph with its instance graph.
In some cases, the message graph is a graph of one object. But in other cases (especially when non-blank embedded embedded resources are included), it can be a graph of many objects. My impression is that at some places in the specification process, the AP authors forgot the graph nature of AS2 and were thinking in terms of plain JSON data trees. Of course, I could be wrong about that, it’s just the impression I have.
There are other places in the AP spec where blank nodes are used. For example, a C2S Create message must use a blank node for the created object. Even if the client provides an id, it MUST be ignored. C2S (partial) Updateshould be a blank node. Using the update target’s id is incorrect because the Update message is not a partial representation of the target, it is a set of instructions about how to update the target. Personally, I think C2S Update should require the same behavior as S2S (full replacement).
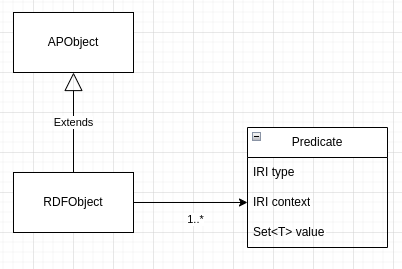
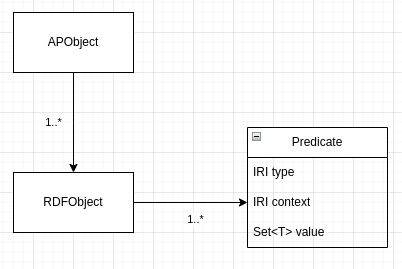
In fact, the behavior comes from the fact that I allow object lists to be sent. There is the type RDFObject, which is a single object like Note, but there is also RDFObjectRevision which is an object that is sort of modularized. An example for such a collection of Organization, Place, PostalAddress, ContactPoint
All Objects in a RDFObjectRevision has the same identifier: <https://schema.org/identifier> "9d317daca74246d4be41b1a37e30ee2a";
And the next layer is RdfRevisionContainer, which contains different versions of RDFObjectRevisions
The clients will in most cases be adapters to existing systems that are not modeled for activityPub.
And this systems are not able to send triggers to the adapter, if new Objects are created. So the adpater has to poll and maybe has to create a bunch of objects with one request.
i avoided this in a first version and always used sparql queries to ensure some consistency, but this went totally wrong for performance reasons
i have to say that with my vision I’m straining the activitypub protocol quite a bit.
Newbie alert: I’m just coming to grips with JSON-LD and RDF. I submitted a couple of JSON-LD actor documents (one from Mastodon 4.1.3 and another I wrote myself) and converted them to N-Quad RDF format. Even with a fairly complex “@context” in both of them, I found that blank nodes were always generated for these properties:
endpoints
attachment
tag
image
icon
Is this expected, since the nodes don’t have explicit IDs?
tag and attachment are just lists with no ID of their own, endpoints is an anonymous object (is that the right terminology, or is it map or graph?) with a sharedInbox property that itself has ID, image and icon have a url property but no separate id property. Also it’s not clear to me that endpoints is actually in the default ActivityStreams vocabulary, as Mastodon’s output is implying.
It’s a URI to a node, but the context doesn’t tell you which terms are valid for that node. Many implementations use a blank node (a node with an anonymous identifier) for endpoints, but one could assign an id to it and share the endpoints node/resource among all actors. With the id, it could be dereferenced independently of the actor data. That could make sense if the endpoints only included the sharedInbox and instance-level OAuth2 URLs, for example.
that’s terrible. i had decided that an AP object always has exactly one subject. but a blank node is also a subject, just an “undefined” one.
that means that if i load an “object” from the triple store, then i have n subjects and not one.
In case of Actor/endpoints i have this statements: