All three of the most-popular AP-based servers (Mastodon, Pleroma, Misskey) use this type of signature in addition to HTTP signatures. These are used to sign the message itself, to allow it to be proxied by other instances to the instances yours doesn’t know about. Example: you follow Eugen on mastodon.social from your instance. His instance obviously sends you (and signs with HTTP signatures) his own posts and replies made by other users on mastodon.social. But if someone from another instance replies to one of his posts, their instance has no idea where to send that reply for it to reach all Eugen’s followers. So mastodon.social proxies these to every instance where there are Eugen’s followers. This way every such instance has complete threads for all these posts. Since mastodon.social doesn’t have the private keys of those users from the other instances, and HTTP signatures depend on the request destination so they can’t be proxied, the HTTP signature is done with Eugen’s key, and you’re supposed to verify the LD-signature to authenticate that the reply was created by whoever it was created.
The signature generation process consists of the following steps, as I understood it:
- Expand the JSON-LD document.
- Convert the expanded JSON-LD document to an RDF dataset.
- Normalize the RDF dataset using the URDNA2015 algorithm.
- Create a JSON-LD document with signature options and perform the steps 1-3 for it too.
- Hash the options normalized RDF dataset, serialized in turtle format, with newlines between the quad strings, in UTF-8, with SHA-256.
- Hash the document normalized RDF dataset same way.
- Concatenate the hashes, in
binary formlowercase hex, in that order. - Sign that byte array with the private key of the user.
- Add the signature to the JSON object like everyone else does that.
- Be happy.
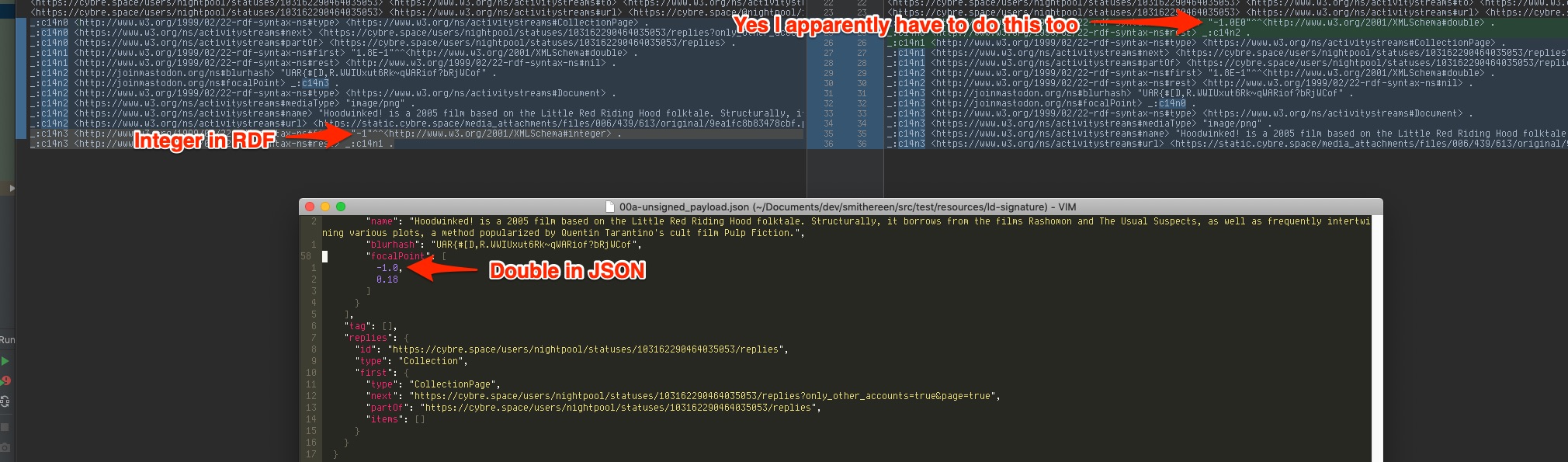
As is usual with this kind of thing, it’s only easy in the specifications. For 1 and 2, there’s a test suite to go along with the JSON-LD spec I used to generate myself some unit tests. I pass all of the expansion tests and all of the important ones among the to-RDF tests (I ignore some IRI resolving edge cases because there aren’t going to be file URIs and such in real life). I represent my RDF datasets as arrays of subject-predicate-object-graph “quads”. For the purpose of the to-RDF tests, I first assert that the array sizes are equal, and then that my actual output contains each of the quads from the expected output, effectively comparing the arrays disregarding their order.
For URDNA2015, there’s also a test suite. I pass some tests from it (42 out of 62 at the time of writing). The issue is that the LD-signature generation algorithm I described above hashes the URDNA2015 output as-is, with Mastodon implementation joining the Turtle-serialized strings with newlines. Because we’re doing hashes, the order of the strings is obviously important since differently-ordered strings will produce different hashes.
None of the specs say anything about the ordering of the RDF quads. The JSON-LD spec doesn’t mention it but the test suite page tells you that you need to compare them using “RDF isomorphism” which, if I understood all that type theory mumbo-jumbo correctly (gosh, it feels like making a Telegram client from scratch again), means you have to disregard the order which is what I do for my tests. The URDNA2015 spec doesn’t say anything about the ordering either. But For each quad, quad, in input dataset: as the last step, even though you sort things internally, kinda implies that you’re supposed to keep the order of the original dataset. The test suite page doesn’t say anything about ordering either.
Interestingly enough, some of the URDNA2015 tests themselves are like this:
Input:
_:b0 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://example.org/vocab#Foo> .
_:b0 <http://example.org/vocab#embed> <http://example.org/test#example> .
Output:
_:c14n0 <http://example.org/vocab#embed> <http://example.org/test#example> .
_:c14n0 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://example.org/vocab#Foo> .
Notice that not only the blank nodes are relabeled, which is the actual purpose of that normalization algorithm (why do we need this in the first place?!), but the lines are also swapped.
If I serialize the RDF quads and then sort the strings lexicographically, that seems to dramatically increase the number of tests passed but some still fail. Is that what I’m supposed to do even though it isn’t written anywhere? Could someone enlighten me please?
p.s. I have to add that the algorithm descriptions in the specs are clearly written with a dynamically-typed language in mind. It was a PITA to convert that into Java, and I might’ve made some mistakes which is why not all URDNA2015 tests pass yet.