It’s me again with my efforts to extend collections. This is somewhat of a continuation of the discussion started in the #fep-400e topic, but I feel like it warrants having a topic (and at some point a FEP) of its own.
Sometimes, it’s useful to have the ability to issue a single request to ask a remote instance “does this collection contain this object?” for an authoritative answer. This can be useful both for collection synchronization and to enforce bilateral relationships.
Example #1. There’s a wall post made by a user from instance A on the wall of a group on instance B (in accordance to my #fep-400e). The user from instance A mentions a user from instance C in a reply to that post. The instance C fetches both the post and the reply to display them to its local user in a notification. How does instance C verify that instance B has approved that parent post?
Example #2. A user from instance A and a user from instance B add each other as friends. They each have a “friends” collection that contains all such connections. Each sends an Add activity to their followers to keep friend lists in sync across instances. How do recipients verify that this relationship was actually established on the other end if they only follow one of the users?
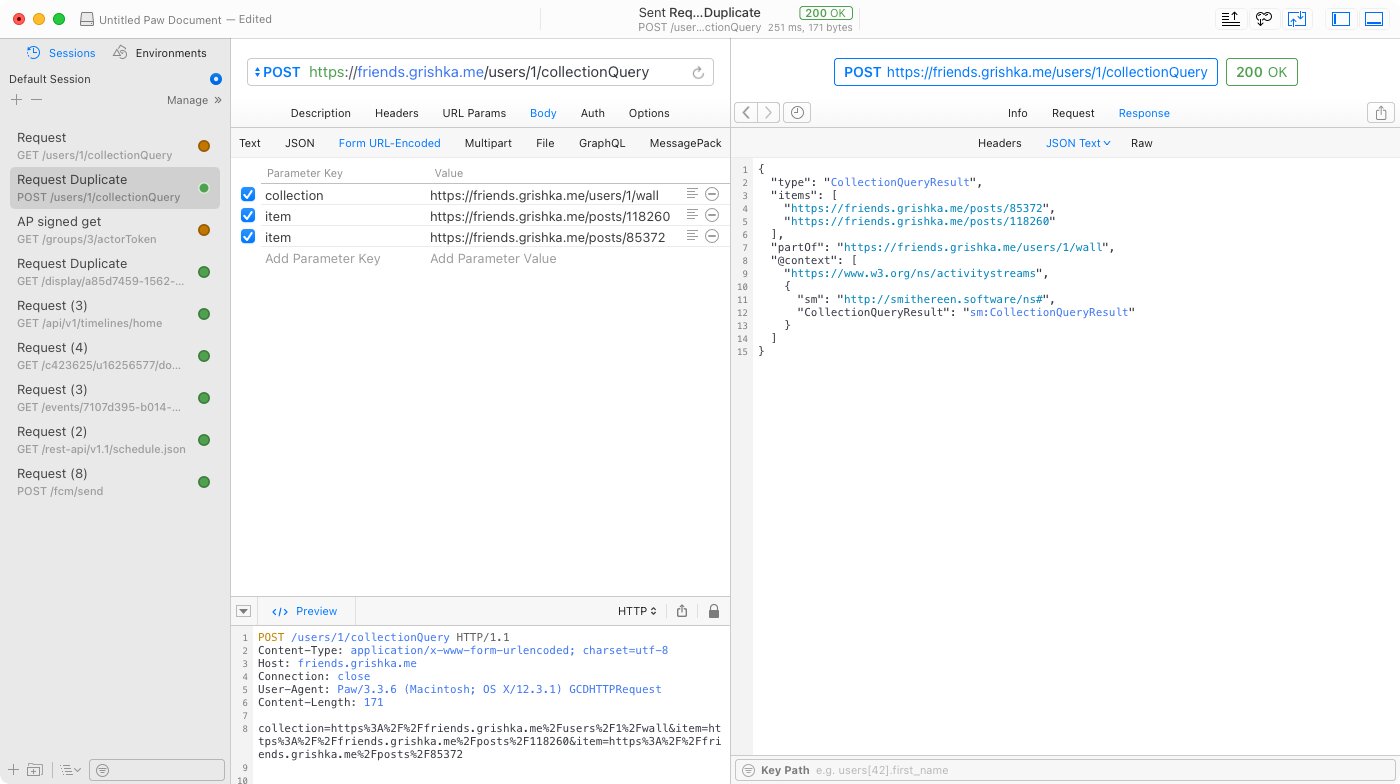
Currently, there’s no non-ugly way to do this — the only way you can get something out of a collection is by going through its pages. I’d like to discuss an easy way to query a collection, for example, using a well-defined query parameter or an HTTP header. You’d send a request to the collection ID URL, specifying the ID of the object you’re checking for, and the response would be one of three discernible states:
- The collection contains the object
- The collection does not contain the object
- Inconclusive — the server doesn’t support responding to these requests